一念起
天涯咫尺
一念灭
咫尺天涯
或许
就算我
追到天涯
去到海角
也再寻不到你
纵情
天下山水
却更是
让我想起你
与之媲美的身影
凤凰岭上
那一轮圆月
不正是你那闪亮的眼睛么
万泉河里
那一带绿水
正如你那扫过我脸颊的长长秀发
昌江的山
融在昌江的水里
昌江的水
流淌在昌江的山间
你在我的梦里
我梦里却没有我


一念起
天涯咫尺
一念灭
咫尺天涯
或许
就算我
追到天涯
去到海角
也再寻不到你
纵情
天下山水
却更是
让我想起你
与之媲美的身影
凤凰岭上
那一轮圆月
不正是你那闪亮的眼睛么
万泉河里
那一带绿水
正如你那扫过我脸颊的长长秀发
昌江的山
融在昌江的水里
昌江的水
流淌在昌江的山间
你在我的梦里
我梦里却没有我
BBR是Google出品并开源的TCP BBR 拥塞控制算法,目前已提交并集成在最新的Linux内核中。而我们使用的VPS服务器特别是国外的vps上安装BBR后,可以明显提高服务器的连接速度,降低丢包。可以说开启BBR后,不管看视频,看网页,还是代理连接,都会提升大幅度的效果。
魔改BBR,则是在Google的原版BBR基础上的修改版本,通过参数的修改,使服提速算法更为激进,比原版BBR有更为明显的提速效果。
安装选择了较为稳定的原生BBR和魔改BBR一键安装脚本,原生BBR一键安装脚本来自秋水逸冰,魔改BBR一键安装脚本来自南琴浪。
安装 shadowsocks
第一条命令
wget --no-check-ce第二条命令
chmod +x shadowsocks.sh第三条命令
./shadowsocks.sh 2>&1 | tee shadowsocks.log中间会提示你输入你的SS SERVER的账号,和端口。不输入就是默认。跑完命令后会出来你的SS客户端的信息。特别注意,由于iphone端的目前只支持到cfb,所以我们选择aes-256-cfb,即7,这一步按回车继续然后需要几分钟的安装过程,请耐心等待出现下面的画面!
使用root用户登录,运行以下命令,命令支持CentOS 6+,Debian 7+。
wget --no-check-certificate https://github.com/teddysun/across/raw/master/bbr.sh && chmod +x bbr.sh && ./bbr.sh安装完成后,脚本会提示需要重启 VPS,输入 y 并回车后重启。
重启完成后,进入 VPS,验证一下是否成功安装最新内核并开启 TCP BBR,输入以下命令:
uname -r查看内核版本,显示为最新版就表示 OK 了
输入指令
sysctl net.ipv4.tcp_available_congestion_control
返回值一般为:
net.ipv4.tcp_available_congestion_control = bbr cubic reno
或者为:
net.ipv4.tcp_available_congestion_control = reno cubic bbr
则成功安装了BBR使用root用户登录,运行以下命令:
Debian
wget --no-check-certificate 'https://github.com/tcp-nanqinlang/general/releases/download/3.4.2.1/tcp_nanqinlang-fool-1.3.0.sh'
bash tcp_nanqinlang-fool-1.3.0.shCentOS
wget --no-check-certificate 'https://raw.githubusercontent.com/tcp-nanqinlang/general/master/General/CentOS/bash/tcp_nanqinlang-1.3.2.sh'
bash tcp_nanqinlang-1.3.2.sh会得到以下提示:
[Info] 选择你要使用的功能:
1.安装内核
2.开启算法
3.检查算法运行状态
4.卸载算发选择1进行安装,安装完后按要求重启服务器,重启完服务器后,在运行脚本
bash tcp_nanqinlang-fool-1.3.0.sh(Debian)
bash tcp_nanqinlang-1.3.2.sh (Centos)选择2,开启算法。开启算法后,可以再输入3检查算法。
选择原生BBR还是魔改BBR
魔改BBR是在原生BBR的基础上改进出来的,但目前并没有稳定性方面的问题,并且网上有测试,魔改BBR的速度会比原生BBR的效果提升大概一倍以上的效果。所以推荐优先安装魔改BBR。
time:O(nlogn)
space:O(n)
Arrays.sort(numbers) 是由merge sort和quick sort组成的,两者时间复杂度都是O(nlogn),quicksort空间复杂度平均O(logn),最坏O(n),mergesort空间复杂度O(n)
import java.util.Arrays;
public class Solution {
// Parameters:
// numbers: an array of integers
// length: the length of array numbers
// duplication: (Output) the duplicated number in the array number,length of duplication array is 1,so using duplication[0] = ? in implementation;
// Here duplication like pointor in C/C++, duplication[0] equal *duplication in C/C++
// 这里要特别注意~返回任意重复的一个,赋值duplication[0]
// Return value: true if the input is valid, and there are some duplications in the array number
// otherwise false
public boolean duplicate(int[] numbers, int length, int[] duplication) {
if (numbers == null || numbers.length == 0) {
return false;
}
Arrays.sort(numbers);
for (int i = 0; i < numbers.length - 1; i++) {
if (numbers[i] == numbers[i+1]) {
duplication[0] = numbers[i];
return true;
}
}
return false;
}
}time:O(n)
space:O(n)
import java.util.HashMap;
public class Solution {
// Parameters:
// numbers: an array of integers
// length: the length of array numbers
// duplication: (Output) the duplicated number in the array number,length of duplication array is 1,so using duplication[0] = ? in implementation;
// Here duplication like pointor in C/C++, duplication[0] equal *duplication in C/C++
// 这里要特别注意~返回任意重复的一个,赋值duplication[0]
// Return value: true if the input is valid, and there are some duplications in the array number
// otherwise false
public boolean duplicate(int numbers[],int length,int [] duplication) {
if (numbers == null || numbers.length == 0) return false;
HashMap<Integer, Integer> map = new HashMap<>();
for (int num : numbers) {
if (map.containsKey(num)) {
duplication[0] = num;
return true;
} else {
map.put(num, 1);
}
}
return false;
}
}根据题意进行交换判断
time:O(n)
space:O(1)
public class Solution {
// Parameters:
// numbers: an array of integers
// length: the length of array numbers
// duplication: (Output) the duplicated number in the array number,length of duplication array is 1,so using duplication[0] = ? in implementation;
// Here duplication like pointor in C/C++, duplication[0] equal *duplication in C/C++
// 这里要特别注意~返回任意重复的一个,赋值duplication[0]
// Return value: true if the input is valid, and there are some duplications in the array number
// otherwise false
public boolean duplicate(int numbers[],int length,int [] duplication) {
if (numbers == null || numbers.length == 0) return false;
for (int i = 0; i < numbers.length; i++) {
while (numbers[i] != i) {
if (numbers[i] == numbers[numbers[i]]) {
duplication[0] = numbers[i];
return true;
}
int temp = numbers[i];
numbers[i] = numbers[temp];
numbers[temp] = temp;
}
}
return false;
}
}import random
choices = ["Rock", "Paper", "Scissors"]
computer = random.choice(choices)
player = False
cpu_score = 0
player_score = 0
while True:
player = input("Rock, Paper or Scissors?").capitalize()
# 判断游戏者和电脑的选择
if player == computer:
print("Tie!")
elif player == "Rock":
if computer == "Paper":
print("You lose!", computer, "covers", player)
cpu_score+=1
else:
print("You win!", player, "smashes", computer)
player_score+=1
elif player == "Paper":
if computer == "Scissors":
print("You lose!", computer, "cut", player)
cpu_score+=1
else:
print("You win!", player, "covers", computer)
player_score+=1
elif player == "Scissors":
if computer == "Rock":
print("You lose...", computer, "smashes", player)
cpu_score+=1
else:
print("You win!", player, "cut", computer)
player_score+=1
elif player=='E':
print("Final Scores:")
print(f"CPU:{cpu_score}")
print(f"Plaer:{player_score}")
break
else:
print("That's not a valid play. Check your spelling!")
computer = random.choice(choices)企业知识管理的理念深入人心 , 其核心目标是促 进企业内部隐性知识的外化以及显性知识的有效组织 和共享利用。显性知识组织方法中以面向知识单元 ( 这里也可以理解为一个个主题 ) 是内容组织的细化和 深入。对于知识密集型企业而言 ,企业的内容资产 ( 如 产品文档、技术文档、流程文档等 ) 数量庞大且分散在 不同的部门 ,如何对这些内容进行描述、组织和整合成 为企业知识管理界需要解决的一个关键问题。IBM 公司在上个世纪末已经遇到数量庞大的技术文档的组 织与管理难题 ,为解决内容生产到发布整个流程中技 术文档的写作、描述、存储、共享与利用等问题 ,提出了DITA
DITA 是一套基于 XML 的面向主题的数字内容 结构化写作与发布方案。具体地讲 ,DITA 为数字内 容的创作定义出一套 DTD 或 Schema , 即为文档撰写 定义了开放标准的适合数字出版物的文档格式 , 在此 基础上为数字内容生产到发布流程提供一套完整的解 决方案。
DITA 基本概念
DITA 的基本原则是面向主题的 , 这里的主题 ( Topic ) 是具体的一个信息单元 ( Unit of Information ) 。
DITA 规范中定义了三种基本主题类型 :
• 概念 ( concept )
• 任务 ( task )
• 参考 ( reference )
概念主题回 答“是什么”的问题 , 介绍产品或服务的相关背景和概 览 ,为用户使用之前提供一些必要信息。任务主题回 答“如何做”的问题 , 通过明确定义的结构来描述完成 一个特定目标所需的方法和步骤。任务主题包括情 境、前提条件、实际步骤、预期结果、举例和下一步行动 等。参考主题提供对相关事实的快速访问。
主 题结构方面 ,任何类型的主题都包含四个基本元素 < title > 、< description > 、< prolog > 和 < body > 。DITA 中的每个信息单元作为独立的可重用的主题 , 脱离上
DITA 架构
• 公共结构
• 跨 信 息 类 型 的 领 域 专 业 词 表
• 类型化主题结构
• 交付上下文
◦ DITA 采用内容与表示分离方 式 ,实现了单源维护、多元发布机制。通过样式模板的 XSL T 转换机制 , 自动输出不同格式类型的知识产品 ( 交付物 ) 。输出格式类型多种多样 , 如 PDF 、HTML 、 CHM 、RTF 等。
DITA 的整体流程
• 结构化内容写作
• 主题仓储
◦ 内容按照所定义的主题类型集中存 储起来 ,每一个主题是一个独立的存储单元 ,最终形成 一个主题仓库。
• DITA 映射
◦ DITA 映射图 ( Map ) 是内容产品的 建造蓝图 ,好比图书的目录 ,其作用是为满足具体信息 需求 ,从内容仓库中调取相关的主题进行“组装”,输出 特定的内容产品。DITA 的映射实质是一个信息构建 的过程 ,将相关主题组织和连接在一起。另外 ,DITA 映射图也是建立主题导航的基础。
• 样式转换与输出
◦ 按照预先设定的样式模板 , 选择输出类型 ,通过 XSL T 转换得到最终产品
DITA不足之处
虽然 DITA 具有面向主题、模块化复用、灵活输出等诸多优点 , 但 结构化写作的技术模式对传统内容创作而言 , 是一种 写作范式上的巨大转变。人们已经习惯于在文字处理 软件撰写文档 ,虽然商业解决方案都力图在用户体验 界面上简化和方便用户的使用 , 但 DITA 本身仍然具 有较高的技术门槛 ,因此没有被广泛接受。
DITA应用
内容结构与重用。考查内容的逻辑结构 , 像文 学体裁之类的创造性写作 , 本身不具有严谨成型的结 构模式 ,而且文学内容基本没有重用性的考虑 ,这就不 适合采用 DITA 方法。DITA 方法的一个核心理念是 主题的重用 ( Reuse ) ,内容重用意味着主题内容本身具 有一定的参考和利用价值 ,因此 DITA 处理的内容应该是选择那些高价值的知识或情报内容。
大规模内容生产与管理。需要处理的内容数量 较大时 ,可以考虑采用 DITA 的结构化处理机制。为 内容预先设定结构模式 ,DITA 使整个内容生产流程 系统工程化和自动化 ,提高了内容管理的质量和效率。 如果数字内容数量较少 , 则没有必要特意设计内容结 构 ,否则采用 DITA 方法的投入会超过内容结构化处 理所带来的好处 ,起不到事半功倍的效果。
协同写作与内容风格。多位作者同时为一个文 档项目编制内容 ,DITA 的结构化预设、内容与表现分 离的处理方式 ,使得作者们在同一套结构化文档规则 下 ,集中精力进行内容的写作和维护 ,保证了内容风格 的一致性。排版和表现方面则由样式模板的 XSL T 转 换机制进行统一化管理 , 这样能够有效提高内容写作 上的协同质量。
DITA讨论
服务指南运用 DITA 方法进行改造的劣势也比较 明显。一开始要求培训学科馆员使用 XML 编辑工具 进行结构化内容创作 , 而且需要掌握 DITA 的一系列 标记语法 ,整体使用门槛较高。选择一些商用的类似 文字处理软件操作界面的所见即所得的 DITA 编辑工 具可以在一定程度上降低使用门槛 , 但 DITA 理念的 接受和理解过程是不可避免的。
另外 DITA 在内容数量越多的情况下优势和效益 体现得越明显 ,而对于中小型图书馆而言 ,自身订购的 信息资源种类和提供的服务方式较少 , 服务指南的撰 写与维护工具就相对简单一些 , 传统的文字编辑工具 即可胜任。这类情况没有必要采用 DITA 方法 , 否则 就把简单问题复杂化了 , 因此要根据图书馆资源数量 和服务手段的具体情况 ,谨慎做出决策。
编辑导读:随着“新基建”的号角,新技术不断涌现,数字化转型成了成了大多数企业的迫切需求。其中,服务数字化转型成为了当务之急。那么,服务数字化转型需要注意哪些问题?用什么方法进行规划?本文作者结合自己对服务数字化的所思所考,对这些问题进行了梳理分析,与大家分享。

2012年和2013年笔者在IBM负责国内CRM解决方案时,就有很多企业,尤其是车企要做服务再造。那时候,我提的建议聚焦在服务产品化,服务生命周期和关键时点的管理上,还比较务虚和难以落地,所以项目基本上最后都不了了之。
最近5,6年,国内市场经历了IT技术、用户需求和企业管理理念的巨大飞跃,同时笔者也花了1年半时间主持了国内最大的数字化服务再造项目,所以在此分享一下自己对服务数字化转型的一些看法。
本服务数字化转型主题由一系列文章组成,本文是第一篇,聚焦在如何定位和规划服务数字化转型。本篇文章介绍了5个方面的内容:
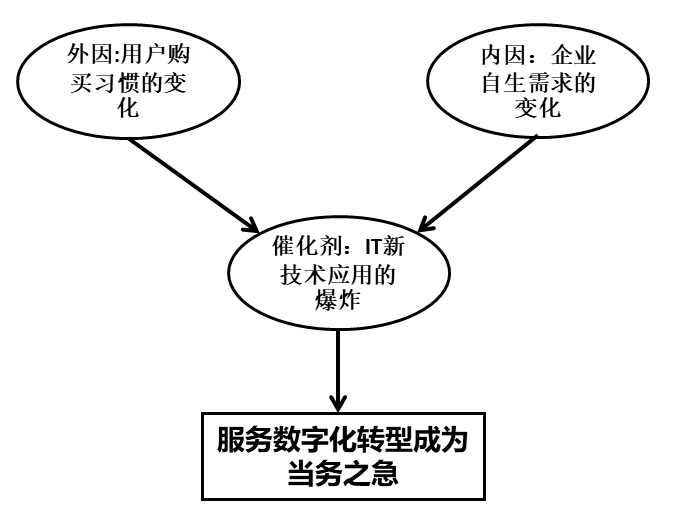
Figure 1 服务数字化转型推手
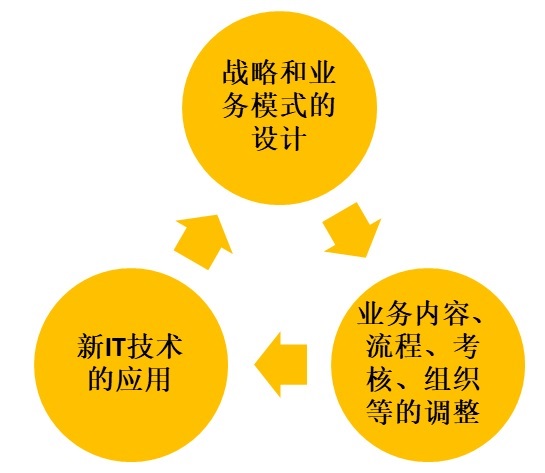
Figure 2 服务数字化涉及的层面
在服务数字化转型过程中,每家企业的起点和现状不一样,每家企业的诉求也不一样,所以企业可以根据自己的情况,选择去做全面彻底的服务数字化转型,还是聚焦在某一点,做局部的提升和改善。
如下图,企业对服务不同的定位,决定了服务数字化转型的不同策略和方法。这个没有对错之分,只是企业最高层对服务未来蓝图的设计不同而已。
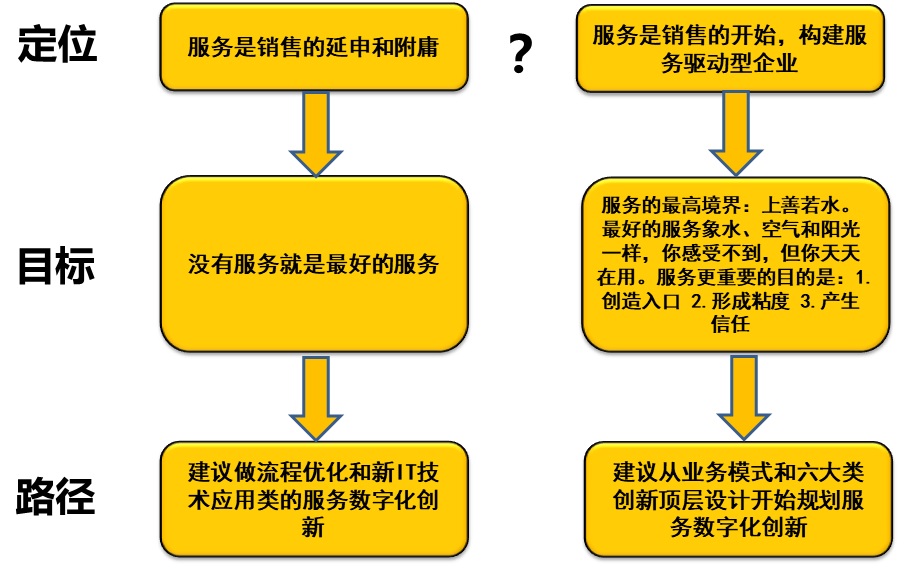
Figure 3 服务定位决定数字化服务再造的方向和实现路径
针对想从战略和业务模式上进行服务数字化转型的企业,下面介绍一种RMB-TP模型,通过这个模型可以去设计和规划落地策略和步骤。
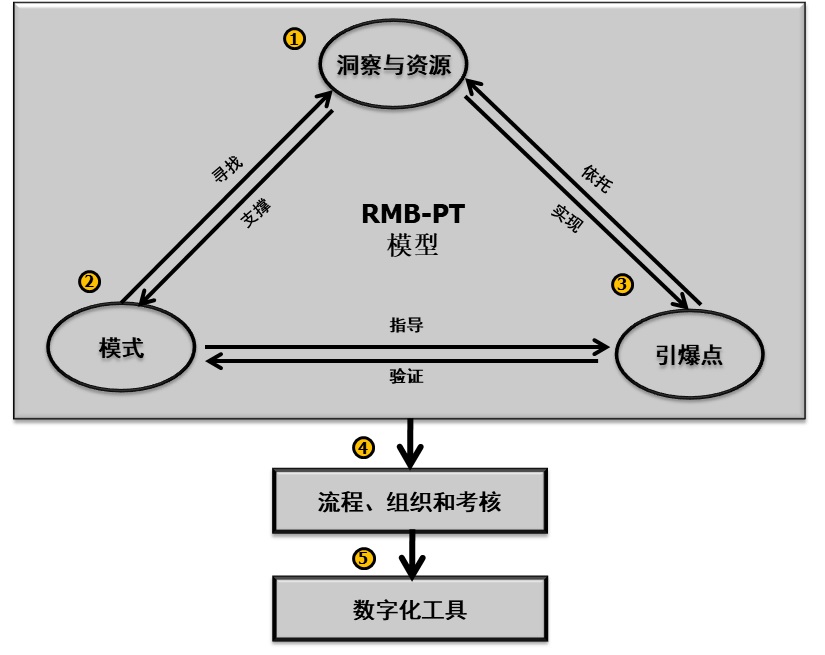
Figure 4 服务数字化转型规划的RMB-PT模型
步骤1:我们首先要对行业方向和竞争对手有个分析和洞察。我们也可以找到标杆企业,向其学习,但我们不必模仿。因为我们模式设计最重要的一点是根据企业自身的资源和特点,设计好自己独特和个性化的服务数字化转型方式。
步骤2:我们根据市场洞察和自身资源的情况,设计适合企业自身特点的服务数字化转型的模式。这会涉及到6个方面的创新和转型:1.服务方式的创新;2.盈利模式的创新;3.服务人员定位和能力的转型; 4.服务支撑体系的创新;5.社群和生态运营创新;6.数字化工具创新
步骤3:在服务数字化转型中,我们需要设定短期目标。即在半年和一年内我们可以在哪些业务上取得可以量化的提升。
步骤4:在模式和引爆点确定后,我们通过优化或再造流程、组织和考核等要素,来确保模式和引爆的业务指标落地。
步骤5:最后,通过目前数字化技术,开发相应的工具,快速部署和加快服务数字化转型落地。
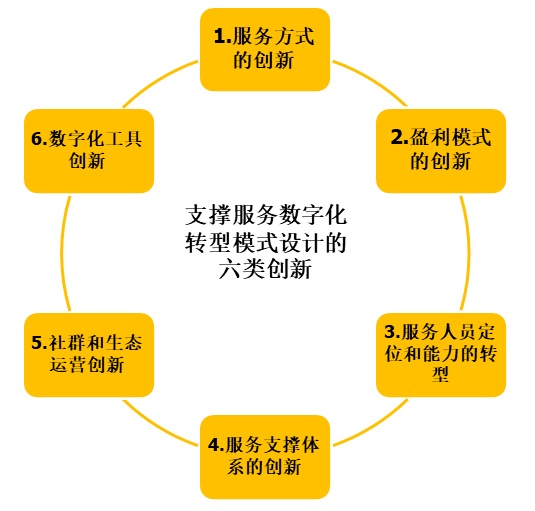
Figure 5 支撑服务数字化转型模式设计的六类创新
如上图所示,想要支撑服务数字化转型的模式设计,我们就需要考虑做六类创新和转型:
笔者将在下篇文章里,详细介绍一下如何设计和规划这六类创新和转型。
本篇文章是服务数字化转型系列文章的第一篇,主要针对要做服务数字化转型的企业,在整体宏观和战略层面上介绍了以下概念:
详情《营销和服务数字化转型 CRM3.0时代的来临》一书。
根据题意从右上或者左下进行遍历找值
time: O(m + n)
public class Solution {
public boolean Find(int target, int [][] array) {
if (array == null || array.length == 0 || array[0] == null || array[0].length == 0) {
return false;
}
int row = 0;
int col = array[0].length - 1;
while (row <= array.length - 1 && col >= 0) {
if (target == array[row][col]) {
return true;
} else if (target < array[row][col]) {
col--;
} else {
row++;
}
}
return false;
}
}逐层遍历,每层中采用二分搜索策略
time: O(mlogn)
public class Solution {
public boolean Find(int target, int [][] array) {
if (array == null || array.length == 0 || array[0] == null || array[0].length == 0) {
return false;
}
for (int i = 0; i < array.length; i++) {
int low = 0;
int high = array[i].length - 1;
while (low <= high) {
int mid = (high - low) / 2 + low;
if (array[i][mid] == target) {
return true;
} else if (array[i][mid] < target) {
low = mid + 1;
} else {
high = mid - 1;
}
}
}
return false;
}
}声纹认证作为生物特征认证的一种,是根据说话人的声波特性进行身份辨识的服务。身份辨识与口音无关,与语言无关,可以用于说话人辨认和说话人确认,广泛应用于金融安全、智能家居、智慧建筑等领域。不同的任务和应用会使用不同的声纹认证技术,如缩小刑侦范围时可能需要辨认技术,而银行交易时则需要确认技术。声纹认证就是把声信号转换成电信号,再用计算机进行识别。声纹认证可以说有两个关键问题,一是特征提取,二是模式匹配(模式识别)。
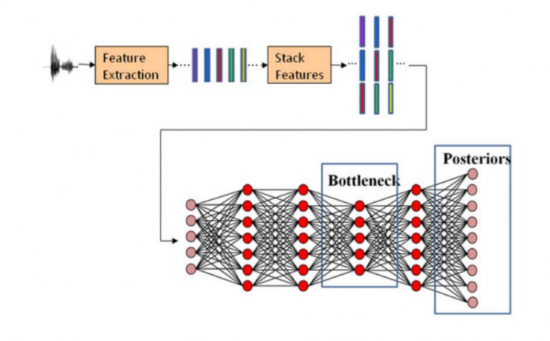
在本次项目中,我们实现了基于MFCC和GMM的声纹认证系统,MFCC:梅尔频率倒谱系数 Mel-Frequency Cepstral Coefficients,Mel频率是基于人耳听觉特性提出来的, 它与Hz频率成非线性对应关系。MFCC则是利用它们之间的这种关系, 计算得到的Hz频谱特征, 一定程度上模拟了人耳对语音的处理特点。GMM:高斯混合模型 Gaussian Mixture Model,GMM模型是单一的高斯密度函数的扩展,可以逼近任意形状的概率密度分布,被广泛应用到语音识别领域。语音信号的特征向量被提取之后,需要对提取的特征向量建模模型训练根据特征参数建立高斯混合模型GMM。
近几十年来,语音处理技术已经得到了迅猛的发展,特别是在语音传输和数字语音存储方面的发展给人类的生活带来了极大的便利。传统的身份确认系统通常利用个人所知道的信息来作为身份确认的依据,如使用密码或者个人物品来判断,比如身份证、密保卡等。但是随着个人账号的不断增多,与之相对应的记忆成本与日俱增,传统方法正面临着巨大的考验。
生物学特性作为身份认证已经被越来越多的运用到人们的日常生活中。常见的生物特征有指纹、人脸、视网膜和声音等[1],在所有的生物特征中,语音作为人类交流最自然的特征之一,其具有与指纹一样的能够识别身份的特性。因此,研究声纹识别(Voiceprint recognition)将可以给人们的日常生活带来极大的便利。
所谓声纹(Voiceprint),是用电声学仪器显示的携带言语信息的声波频谱[2]。人类语言的产生是人体语言中枢与发音器官之间一个复杂的生理物理过程,人在讲话时使用的发声器官–舌、牙齿、喉头、肺、鼻腔在尺寸和形态方面每个人的差异很大,所以任何两个人的声纹图谱都有差异。每个人的语音声学特征既有相对稳定性,又有变异性,不是绝对的、一成不变的。这种变异可来自生理、病理、心理、模拟、伪装,也与环境干扰有关。尽管如此,由于每个人的发音器官都不尽相同,因此在一般情况下,人们仍能区别不同的人的声音或判断是否是同一人的声音[3]。
优点:
缺点:
在自动总机系统中,把身份的声纹辨认和关键词检出器结合起来,可以在姓名自动拨号的同时向受话方提供主叫方的身份信息。前者用于身份认证,后者用于内容认证。同样,声纹识别技术可以在呼叫中心(Call Center)应用中为注册的常客户提供友好的个性化服务。
鉴于密码的安全性不高,可以用声纹识别技术对电话银行、远程炒股等业务中的用户身份进行确认,为了提供安全性,还可以采取一些其他措施,如密码和声纹双保险,如随机提示文本用文本相关的声纹识别技术进行身份确认(随机提示文本保证无法用事先录好的音去假冒),甚至可以把交易时的声音录下来以备查询。
对于各种电话勒索、绑架、电话人身攻击等案件,声纹辨认技术可以在一段录音中查找出嫌疑人或缩小侦察范围;声纹确认技术还可以在法庭上提供身份确认(同一性鉴定)的旁证。在监狱亲情电话应用中,通过采集犯人家属的声纹信息,可有效鉴别家属身份的合法性。
声纹辨认技术可以察觉电话交谈过程中是否有关键说话人出现,继而对交谈的内容进行跟踪(战场环境监听);在通过电话发出军事指令时,可以对发出命令的人的身份进行确认。
机密场所的门禁系统等。又如声纹识别确认可用于信用卡、银行自动取款机、门、车的钥匙卡、授权使用的电脑、声纹锁以及特殊通道口的身份卡,把声纹存在卡上,在需要时,持卡者只要将卡插入专用机的插口上,通过一个传声器读出事先已储存的暗码,同时仪器接收持卡者发出的声音,然后进行分析比较,从而完成身份确认。同样可以把含有某人声纹特征的芯片嵌入到证件之中,通过上面所述的过程完成证件防伪。
基于语音处理技术,国内外在语音识别方面发展的非常迅速,例如我国的科大讯飞[4]、Google的云语音API[5]、微软的Bing语音[6],但是在声纹识别方面的发展相对缓慢。声纹认证逐渐被作为一种双因子认证应用于日常的软件中,例如微信、支付宝的声纹登录,科大讯飞的“声纹认证+人脸识别P2P转帐”等。2015年诞生于美国硅谷的speakIn,目前已经是行业领先的声纹识别与身份安全解决方案提供商。
除了现有的产品,各大公司和科研机构还提供了一些声纹识别库,例如Microsoft Speaker Recognition API[7]、IDIAP Research Institute的Bob[8]、Will Drevo基于Python和Numpy开发的Dejavu[9]等。
(a) Microsoft Speaker Recognition API
微软开发出的这个API识别较为精准,而且处理速度较快,但由于其用到的口令串是标准的,攻击者能提前录制这些短语,从而入侵账户。此外,该服务是非开源付费使用的。
(b) Bob
Bob是由Switzerland的一家名为Idiap的研究机构里面的生物特征安全和隐私保护小组开发的一套声纹识别工具箱。但是该工具箱安装会占用大量空间和内存,并且语音处理的时长较长。Dejavu在匹配声音样本上十分精确,并且其对音频的处理时间非常的短,
(c) Dejavu
Dejavu是一个轻量级、易用、准确的Python音频指纹库,由麻省理工大学的Will Drevo基于Python and Numpy开发,因此本系统就是基于该音频指纹库实现。
1976年德州仪器(Texas Instruments)制作了第一个说话人识别的原型[10]。后来,NIST(National Institute of Standard and Technology)在语音处理方面做出了极大的贡献。声纹识别的发展归功于特征提取和建模两种技术的进步,早期的与文本相关的说话人识别使用动态时间弯曲(DTW)和模板匹配技术。最近对说话人识别的研究主要集中在与文本无关的说话人识别方面。特征提取技术主要基于短时语音帧分析,语音信号被设定为准平稳的,一般情况下语音的帧长为8-30ms,采样频率一般为8kHz-16kHz。倒谱分析和梅尔倒谱分析(MFCC)是说话人识别中最常用的短时分析方法,线性预测(LP)并不常用,但是很多时候常和MFCC结合来使用。
常用的建模方法包括高斯混合模型(GMM)[11],隐马尔科夫模型(HMM)[12],支持向量机模型(SVM)[13],矢量量化模型(VQ)[14]和人工神经元网络(ANN)[11]。
HMM常被用做与文本相关的说话人确认,而GMM、SVM、VQ主要用做与文本无关的说话人识别。其中GMM模型被认为是现在最优秀的建模方法。高斯混合模型是一种高斯概率密度函数(PDF)加权和的向量集。常被看做是单状态连续隐形马尔科夫模型,或者看作为“软”矢量化模型。
随着高斯混合模型技术的快速发展,支持向量机技术逐渐被取代。现在运用最多的技术是使用MFCC特征向量和基于GMM模型的识别,这两项技术到目前仍然是最先进的技术。所以本系统采用的就是采用MFCC特征向量和基于GMM模型的声纹识别。
声纹认证一般分为用户注册过程和用户登录认证过程:
在用户注册过程中,首先对用户输入的用户名和文本口令进行记录,之后对用户所处的背景噪音进行记录,从语料库中随机抽取单词生成临时口令串(temporary password string),提示用户朗读该口令串进行语音注册。使用LTSD(long-term spectral divergence)[16]对所记录到的语音进行背景噪声去除。对去噪后的音频进行语音识别,将识别结果与临时口令串进行模糊匹配(Fuzzy matching),若达到判断阈值则接受这段语音,反之,则重新生成新的口令串让用户朗读。提取音频信号的梅尔频率倒谱系数[17](Mel-Frequency Cepstral Coefficients, MFCC)特征并进行正则化表示。根据特征参数用最大期望算法(Expectation Maximization Algorithm, EM算法)为注册用户建立高斯混合模型[18](Gaussian Mixture Model, GMM)。
在用户登录认证过程,提示待认证用户输入用户名和文本口令,从语料库中随机抽取单词生成临时口令串,提示待认证用户朗读该口令串,使用LTSD对所记录到的语音进行背景噪声去除。对去噪后的音频进行语音识别,将识别结果与临时口令串进行模糊匹配,若达到判断阈值则接受这段语音,反之,则重新生成新的口令串让待认证用户朗读。提取音频信号的MFCC特征并进行正则化表示。根据特征参数用EM算法为注册用户建立GMM模型,与注册用户库的GMM模型进行对数似然估计,若满足阈值,则认为用户是合法用户准许用户进入,反之,则拒绝用户登入系统。
根据对识别时所用的语音内容要求的不同,可将声纹识别分为2类[19]:与文本有关(text-dependent)、与文本无关(text-independent)。与文本有关的声纹识别需要在用户注册时就确定识别所用的发音内容,由于文本内容是已知的,攻击者则可以通过悄悄录音、诱导用户说指定文字等手段,窃取到用户的登录声纹,基于此,攻击者就能轻而易举的进入系统。而本文设计的系统采用的是与文本无关机制,用户在注册、登录时使用的临时口令串都是随机生成的,系统是通过提取用户的声音特征并与之前录入的特征进行匹配,即使攻击者对用户进行录音也无法窃取用户的声纹信息从而登录系统。
有一种潜在的攻击类型就是中间人攻击,攻击者可能监听该系统的客户端和服务器端,当用户进行注册时,客户端会将用户音频文件发送回后台服务器端,中间人在这时会拦截该音频文件,并将其篡改成自己的音频文件发送回服务器端,这样,攻击者可以通过自己的声纹信息登录系统。为此,本系统设计了一种防止中间人攻击的机制,客户端每次将音频文件发送给服务器端之前,进行数字签名操作,用自己的RSA私钥签署音频文件的SHA256散列[20],并将音频文件连同数字签名一起发送给服务器端,若中间人对该音频文件进行篡改,则服务器端会验证失败。
Linux环境,Fedora 27 64bit
Python2.7,Mysql
VMware® Workstation 14 Pro,WIN
Pycharm
Flask(http://docs.jinkan.org/docs/flask)
Dejavu (https://github.com/worldveil/dejavu)
实现一个BS架构的声纹入库与采集系统(B端负责显示和声纹采集,S端负责声纹入库、匹配、计算等多个操作)
分成Server端和Client,为了方便模拟演示,我们使用两个Fedora系统分别模拟,添加好所有依赖包
基于Flask框架实现了一个BS架构,具体原理看Flask官方文档,简单来说就是搭建一个不断轮询、等待C端连接的B端服务机,

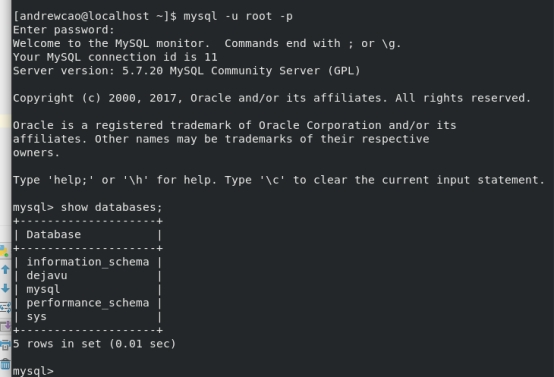
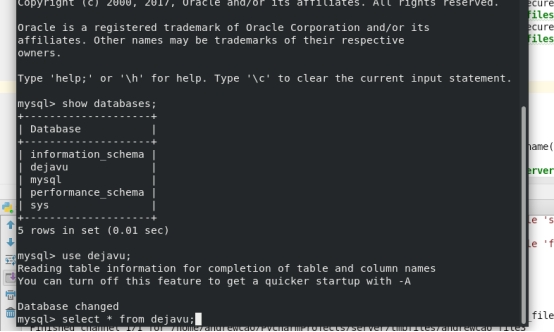
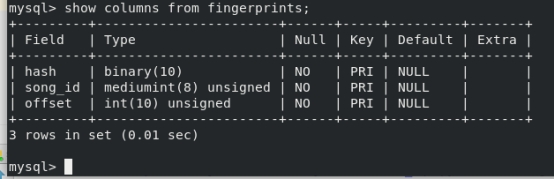
登录界面:
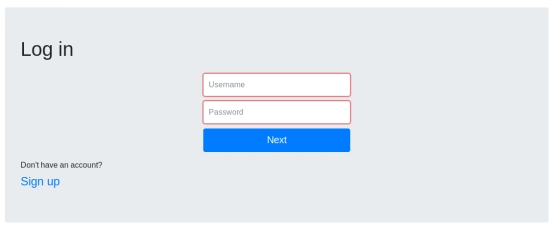
注册界面:
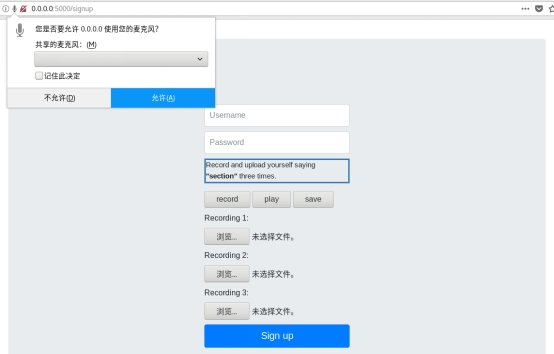
录音:
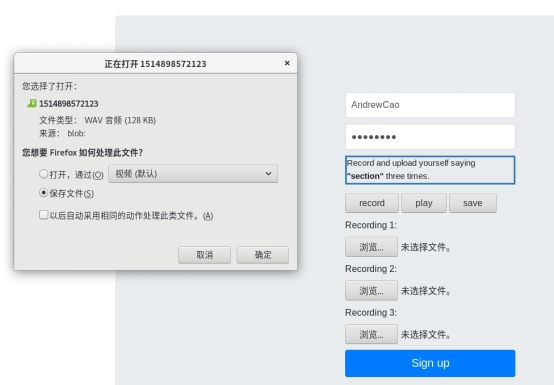
上传录音文件:
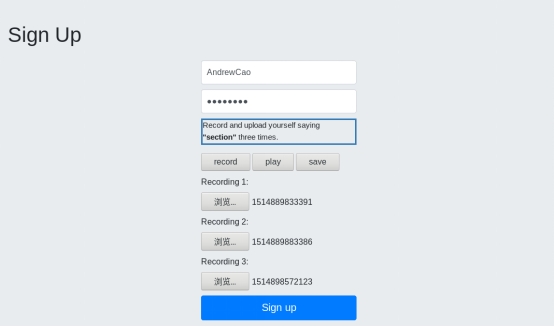
登录:
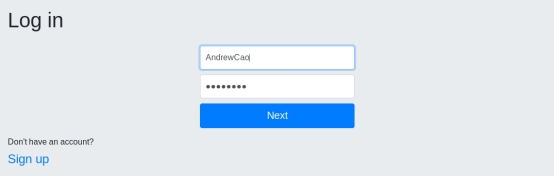
上传录音文件:
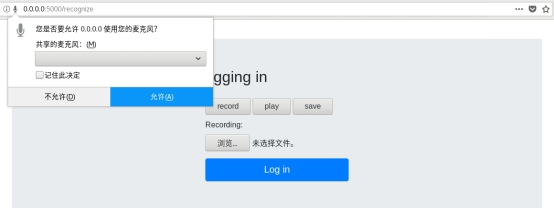
音频识别:
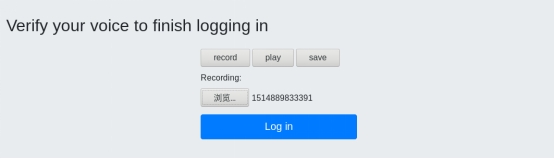
登录成功

声纹认证技术为现在的身份鉴别提供了非常有力的、可靠的解决途径。有着深远的 社会价值、经济价值。也对我国的战略安全,信息安全有着重要的意义。是各国正在发 展的重点战略技术。声纹认证技术作为生物认证技术的重要分支已经引起科研机构和企 业界的高度重视,前景非常乐观。 在前人理论的基础上,经过几个月的努力工作,本文在详细的分析了声纹认证理论的基础上,完成了与文本有关声纹辨认模式和算法的构建,并进行了具体的实验。
本文研究的内容是基于MFcc倒谱系数和高斯混合模型(GMM)的说话人识别系统。其中主要是针对说话人识别所采用的特征向量作了研究,提出了在普通倒谱系数的提取过程中使用音调特性来进行特征提取的方案,即用Mel频率刻度对频率轴进行弯折,从而得到了Mel频率倒谱系数(MFCC),并给出了MFCC倒谱系数的具体提取过程和算法。由于传统的倒谱特征参量提取方法主要是基于LPcc特征,本文通过实验验证了MFcc倒谱特征的系统识别性能略好于LPcc倒谱特征的性能,所以在MFcc特征的基础上对识别过程中所使用的特征作了改进。
本文讨论的基于高斯混合模型的说话人识别系统,该系统的一个主要特点就是文本无关性。本文详细分析了梅尔倒谱系数的提取,以及高斯混合模型的建立、识别过程。从实验中我们也发现,识别的性能还和麦克的质量有很大关系,一个优质的麦克对提高识别率有着关键性的影响;环境的因素也非常重要,最理想的环境是宽敞的安静的开放空间,这里不仅没有回音,噪音也相对较小。 尽管声纹认证技术已经进行了很多年,也取得了很大的发展,但总的来说,想要真正的广泛应用,还有很长的路要走。
由于说话人认证是一个比较复杂的问题,受时间,空间和环境的影响较大,要解决这个问题,一方面要选取较高鲁棒性的特征参量,另一方面要联合多个不同特征的优势,将不同的特征结合起来构成复合特征向量来使用,而所有的这些都需要在今后的工作中加以研究和实践。
声纹认证也和其他认证一样,也向着深度学习的方向发展,但是又和语音识别稍有差异,传统算法和模型在声纹认证中还占有相当大的比重。
下图是Fred Richardson在论文中提出的声纹识别的深度学习模型示意
深度学习的效果还是有的,下图就是各种方法的一种比较,也就说,将来实时声纹识别将会有比较大的突破。

但是难度也很大,因为深度学习是基于数据驱动的模型,需要庞大的数据,这些数据最好是真实场景的数据,以及对数据的精确标注,这些都是很费钱很费人的事情。而且声纹识别训练库的建立,至少要保证性别比例分布为50%±5%,包含有不同年龄段、不同地域、不同口音、不同职业。同时,测试样本应该涵盖文本内容是否相关、采集设备、传输信道、环境噪音、录音回放、声音模仿、时间跨度、采样时长、健康状况和情感因素等影响声纹识别性能的主要因素。
也就是说,声纹认证对数据的要求其实比语音识别还要高很多,这本身就是个很大的门槛,也是突破声纹认证,真正能让声纹认证落地千家万户的核心因素。希望有一天,说话人认证技术能够真正成熟起来,与其它技术结合起来在现实生活中大放异彩。
爬虫基本可以分3类:
Nutch是apache旗下的一个用Java实现的开源索引引擎项目,通过nutch,诞生了hadoop、tika、gora。Nutch的设计初衷主要是为了解决下述两个问题:
Nutch1.2版本之后,Nutch已经从搜索引擎演化为网络爬虫,演化为两大分支版本:1.X和2.X,最大区别在于2.X对底层的数据存储进行了抽象以支持各种底层存储技术,其中:
Nutch的编译安装需要JDK、Ant等环境,为此本次使用的环境和工具如下:
本次JDK使用1.8.0_161,在Oracle官网http://www.oracle.com/technetwork/java/javase/downloads/index.html 可以下载
首次使用需要设置环境变量,在~/.bashrc的末尾加入以下内容:
#set jdk environment
export JAVA_HOME=/java/jdk1.8.0_161
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH然后使用source ~/.bashrc命令使得环境变量生效。


Nutch分为bin和src,bin是运行包、src是源码包,本次我们使用nutch-1.9源码包自己编译,推荐使用SVN进行安装,SVN checkout出来的有pom.xml文件,即maven文件。
$ sudo apt install subversion
$ svn co https://svn.apache.org/repos/asf/nutch/tags/release-1.9
到Ant官网 http://ant.apache.org/bindownload.cgi 下载最新版的Ant。

同样也需要设置环境变量
#set ant environment
export ANT_HOME=/ant/ant-1.9.10
export PATH=$PATH:$ANT_HOME/bin

略
把 conf/下的 nutch-site.xml.template复制一份,命名为nutch-site.xml,在里面添加配置:
<property>
<name>http.agent.name</name>
<value>My Nutch Spider</value>
</property>
<property>
<name>plugin.folders</name>
<value>$NUTCH_HOME/build/plugins</value>
</property>$NUTCH_HOME是指nutch源码的根目录,例如我的是/home/andrewcao95/Desktop/release-1.9



生成Eclipse项目文件,即.project文件,使用如下命令
ant eclipse耐心等待,这个过程ant会根据ivy从中心仓库下载各种依赖jar包,可能要几分钟。这里特别要注意网络通畅,学院的网络可能存在一定的问题,导致很多jar包无法访问,最终会导致编译失败。同时要注意原来的配置文件中包的下载地址会发生变化,为此需要根据报错指令进行相对应的调整。


解决了上述问题之后,很快就能编译成功

按照RunNutchInEclipse的教程指导,很快就能导入项目。之后我们就能看到Nutch项目的完整源代码

源码导入工程后,并不能执行完整的爬取。Nutch将爬取的流程切分成很多阶段,每个阶段分别封装在一个类的main函数中。我们首先运行Nutch中最简单的流程:Inject。
我们知道爬虫在初始阶段是需要人工给出一个或多个url,作为起始点(广度遍历树的树根)。Inject的作用,就是把用户写在文件里的种子(一行一个url,是TextInputFormat),插入到爬虫的URL管理文件(crawldb,是SequenceFile)中。
从src文件夹中找到org.apache.nutch.crawl.Injector类,可以看到,main函数其实是利用ToolRunner,执行了run(String[] args)。这里ToolRunner.run会从第二个参数(new Injector())这个对象中,找到run(String[] args)这个方法执行。从run方法中可以看出来,String[] args需要有2个参数,第一个参数表示爬虫的URL管理文件夹(输出),第二个参数表示种子文件夹(输入)。对hadoop中的map reduce程序来说,输入文件夹是必须存在的,输出文件夹应该不存在。我们创建一个文件夹 urls,来存放种子文件(作为输入)。在seed.txt中加入一个种子URL。


指定一个文件夹crawldb来作为URL管理文件夹(输出)。有一种简单的方法来指定args,直接在main函数下加一行:
args=new String[]{"/home/andrewcao95/Desktop/release-1.9/crawldb","/home/andrewcao95/Desktop/release-1.9/urls"};
运行该类,可以看到运行成功。

读取爬虫文件:

查看里面的data文件
vim /home/andrewcao95/Desktop/release-1.9/crawldb/current/part-00000/data 
这是一个SequenceFile,Nutch中除了Inject的输入(种子)之外,其他文件全部以SequenceFile的形式存储。SequenceFile的结构如下:
key0 value0
key1 value1
key2 value2
......
keyn valuen以key value的形式,将对象序列(key value序列)存储到文件中。我们从SequenceFile头部可以看出来key value的类型。
上面的SequenceFile中,可以看出key的类型是org.apache.hadoop.io.Text,value的类型是org.apache.nutch.crawl.CrawlDatum。
首先我们需要读取SequenceFile的代码,在src/java里新建一个类org.apache.nutch.example.InjectorReader,代码如下:
package org.apache.nutch.example;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import org.apache.nutch.crawl.CrawlDatum;
import java.io.IOException;
public class InjectorReader {
public static void main(String[] args) throws IOException {
Configuration conf=new Configuration();
Path dataPath=new Path("/home/andrewcao95/Desktop/release-1.9/crawldb/current/part-00000/data");
FileSystem fs=dataPath.getFileSystem(conf);
SequenceFile.Reader reader=new SequenceFile.Reader(fs,dataPath,conf);
Text key=new Text();
CrawlDatum value=new CrawlDatum();
while(reader.next(key,value)){
System.out.println("key:"+key);
System.out.println("value:"+value);
}
reader.close();
}
} 得到的运行结果如图所示:

我们可以看到,程序读出了刚才Inject到crawldb的url,key是url,value是一个CrawlDatum对象,这个对象用来维护爬虫的URL管理信息,我们可以看到一行Status: 1 (db_unfetched) ,这表示表示当前url为未爬取状态,在后续流程中,爬虫会从crawldb取未爬取的url进行爬取。
在爬取之前,我们先修改一下conf/nutch-default.xml中的一个地方,这个值会在发送http请求时,作为User-Agent字段。


在org.apache.nutch.crawl中新建一个Crawl.java文件,代码如下所示
package org.apache.nutch.crawl;
import java.util.*;
import java.text.*;
import org.apache.commons.lang.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.nutch.parse.ParseSegment;
import org.apache.nutch.indexer.IndexingJob;
import org.apache.nutch.util.HadoopFSUtil;
import org.apache.nutch.util.NutchConfiguration;
import org.apache.nutch.util.NutchJob;
import org.apache.nutch.fetcher.Fetcher;
public class Crawl extends Configured implements Tool {
public static final Logger LOG = LoggerFactory.getLogger(Crawl.class);
private static String getDate() {
return new SimpleDateFormat("yyyyMMddHHmmss").format
(new Date(System.currentTimeMillis()));
}
public static void main(String args[]) throws Exception {
Configuration conf = NutchConfiguration.create();
int res = ToolRunner.run(conf, new Crawl(), args);
System.exit(res);
}
@Override
public int run(String[] args) throws Exception {
/*种子所在文件夹*/
Path rootUrlDir = new Path("/home/andrewcao95/Desktop/release-1.9/urls");
/*存储爬取信息的文件夹*/
Path dir = new Path("/home/andrewcao95/Desktop/release-1.9","crawl-" + getDate());
int threads = 50;
/*广度遍历时爬取的深度,即广度遍历树的层数*/
int depth = 2;
long topN = 10;
JobConf job = new NutchJob(getConf());
FileSystem fs = FileSystem.get(job);
if (LOG.isInfoEnabled()) {
LOG.info("crawl started in: " + dir);
LOG.info("rootUrlDir = " + rootUrlDir);
LOG.info("threads = " + threads);
LOG.info("depth = " + depth);
if (topN != Long.MAX_VALUE)
LOG.info("topN = " + topN);
}
Path crawlDb = new Path(dir + "/crawldb");
Path linkDb = new Path(dir + "/linkdb");
Path segments = new Path(dir + "/segments");
Path indexes = new Path(dir + "/indexes");
Path index = new Path(dir + "/index");
Path tmpDir = job.getLocalPath("crawl"+Path.SEPARATOR+getDate());
Injector injector = new Injector(getConf());
Generator generator = new Generator(getConf());
Fetcher fetcher = new Fetcher(getConf());
ParseSegment parseSegment = new ParseSegment(getConf());
CrawlDb crawlDbTool = new CrawlDb(getConf());
LinkDb linkDbTool = new LinkDb(getConf());
// initialize crawlDb
injector.inject(crawlDb, rootUrlDir);
int i;
for (i = 0; i < depth; i++) { // generate new segment
Path[] segs = generator.generate(crawlDb, segments, -1, topN, System
.currentTimeMillis());
if (segs == null) {
LOG.info("Stopping at depth=" + i + " - no more URLs to fetch.");
break;
}
fetcher.fetch(segs[0], threads); // fetch it
if (!Fetcher.isParsing(job)) {
parseSegment.parse(segs[0]); // parse it, if needed
}
crawlDbTool.update(crawlDb, segs, true, true); // update crawldb
}
if (LOG.isInfoEnabled()) { LOG.info("crawl finished: " + dir); }
return 0;
}
} 
通过上述代码可以执行一次完整的爬取,程序运行结果如下所示:



运行成功,对网站(http://pku.edu.cn/)进行了2层爬取,爬取信息都保存在/tmp/crawl+时间的文件夹中

欢迎使用 WordPress。这是您的第一篇文章。编辑或删除它,然后开始写作吧!